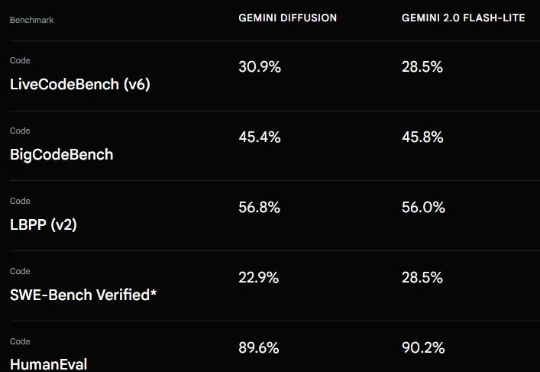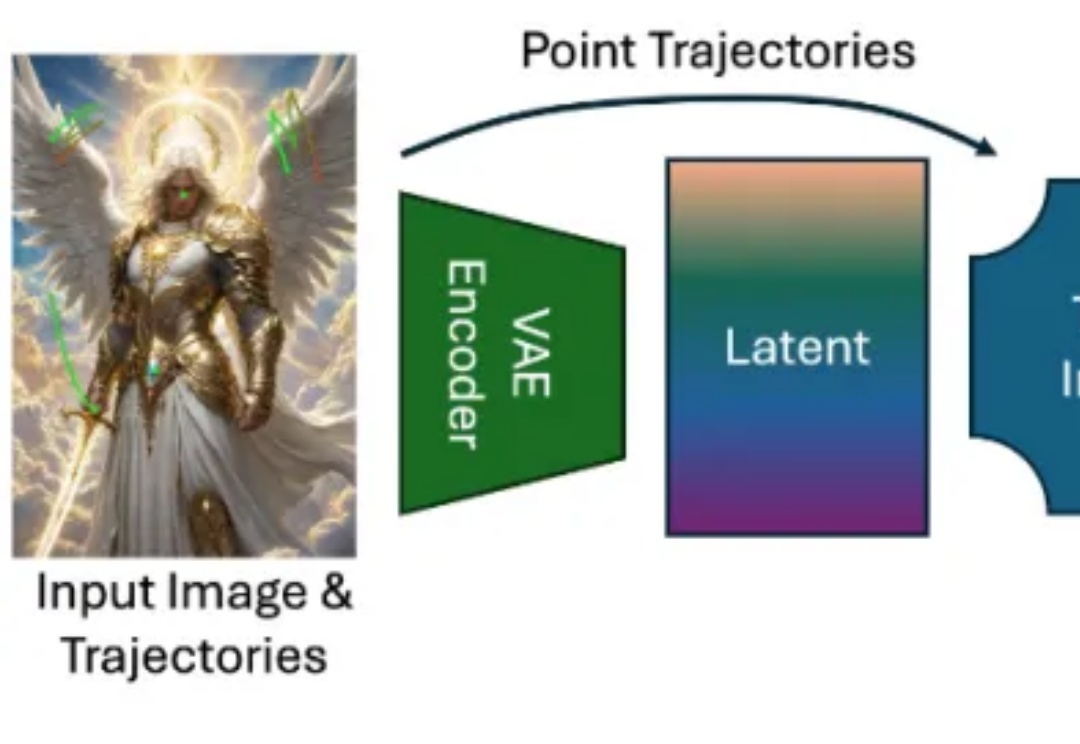
画到哪,动到哪!字节跳动发布视频生成「神笔马良」ATI,已开源!
画到哪,动到哪!字节跳动发布视频生成「神笔马良」ATI,已开源!近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。
来自主题: AI技术研报
9055 点击 2025-07-03 10:07